Case Study
Introduction
Cerebellum is a drop-in infrastructure and library for scalable realtime applications. Whether starting from scratch or integrating an existing application, Cerebellum enables developers to move from development to fully scalable deployment in just a few simple steps.
Alongside our ready-made infrastructure, we offer a Software Development Kit (SDK) and a production-ready WebSocket server, empowering developers to deploy quickly and efficiently without the hassle of managing cloud platforms or connections.
Background: Realtime
Let’s take a step back to understand the concept of realtime. Realtime is the instantaneous exchange of data. Instantaneous in computing terms means to be perceived as instantaneous. This metric can vary depending on the constraints of the application, but instantaneous is commonly considered to be below 100-millisecond latency.
Realtime applications are divided into two main categories, each with distinct time constraints or “deadlines” that must be met to ensure a proper response.
Realtime Categories
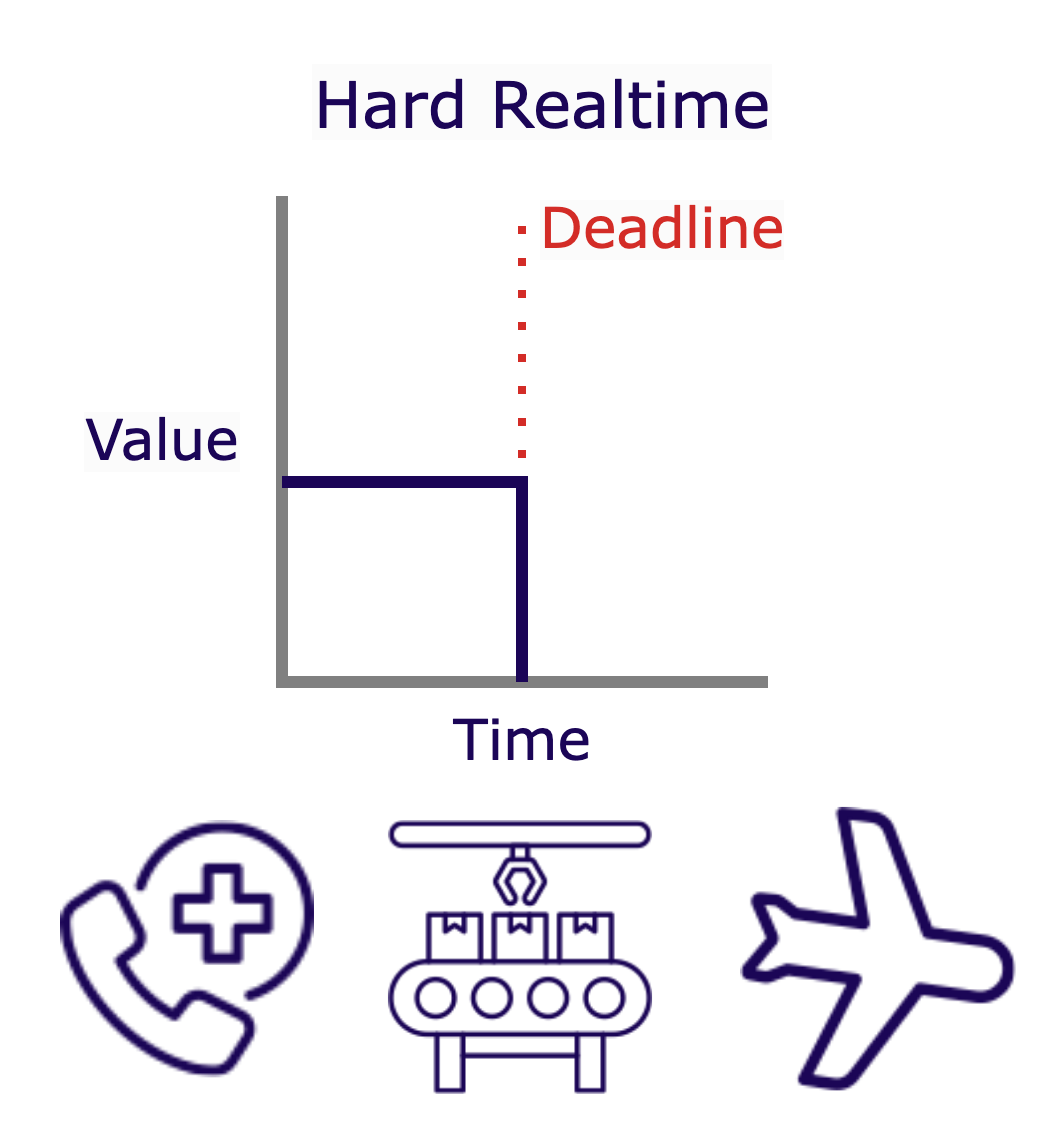
Hard realtime applications demand absolute performance where timing is crucial, and deadlines must be met without exception. Missing a deadline in a hard realtime system can lead to total system failure and catastrophic consequences, often involving safety hazards or physical damage. The importance of a task is directly tied to meeting its deadline; missing it can render the task's value null. Examples of such systems include emergency medical devices, industrial automation systems, and flight control systems.
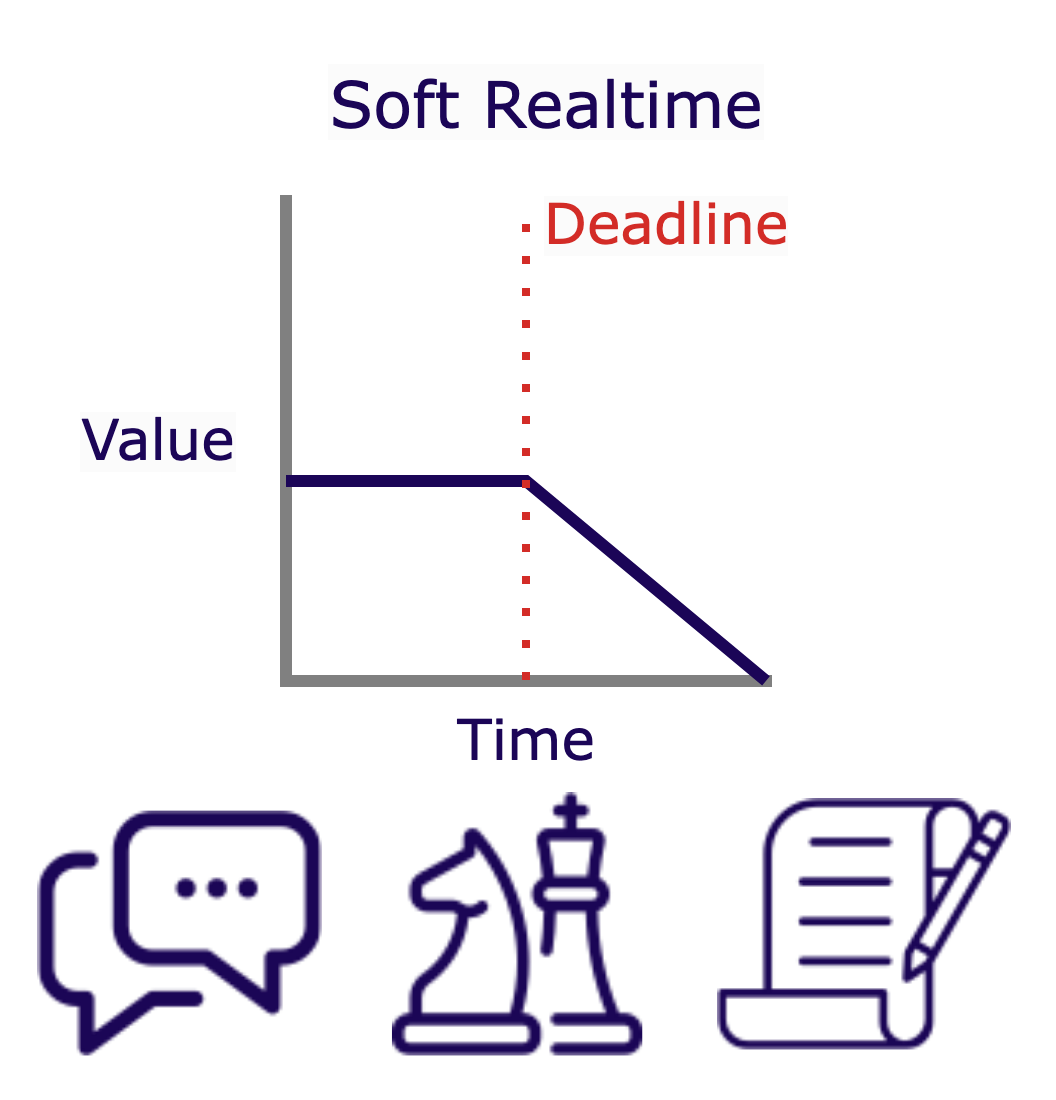
In soft realtime applications, missing a deadline results in a degradation of service quality, which can negatively impact user experience and be quite frustrating. However, it does not lead to system failure or significant harm. The value of a task is somewhat correlated with meeting the deadline—if missed, the value decreases but does not become null. Examples of soft realtime systems include messaging apps, online multiplayer games, and collaborative editors. Cerebellum is designed specifically for soft realtime applications.
Before we dive deeper into Cerebellum, we need to review a few key techniques and technologies for building realtime web applications.
Realtime Techniques & Technologies
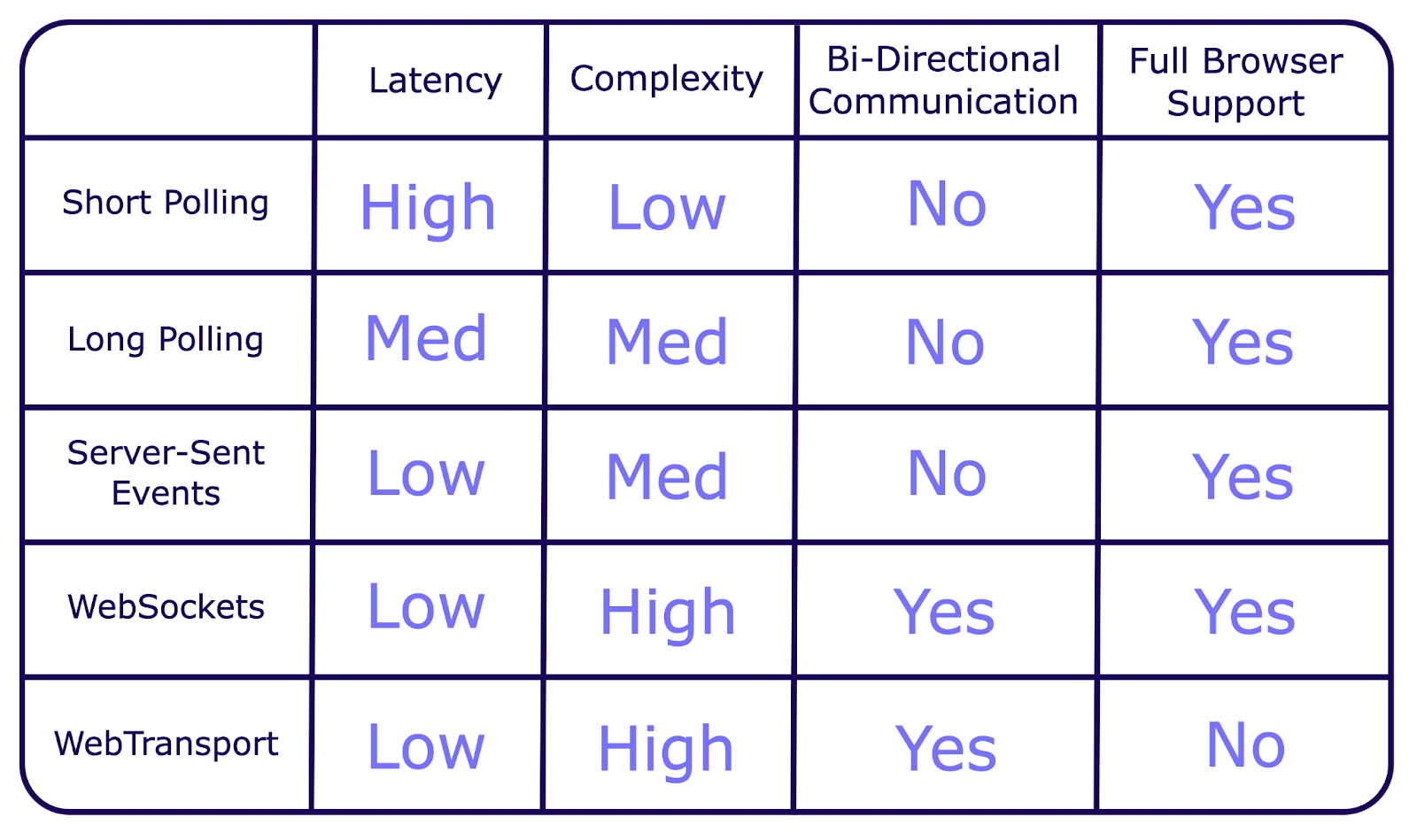
Short polling involves sending HTTP requests at intervals to check for new data. While simple to implement, it can create unnecessary network traffic and server load when no new updates are available.
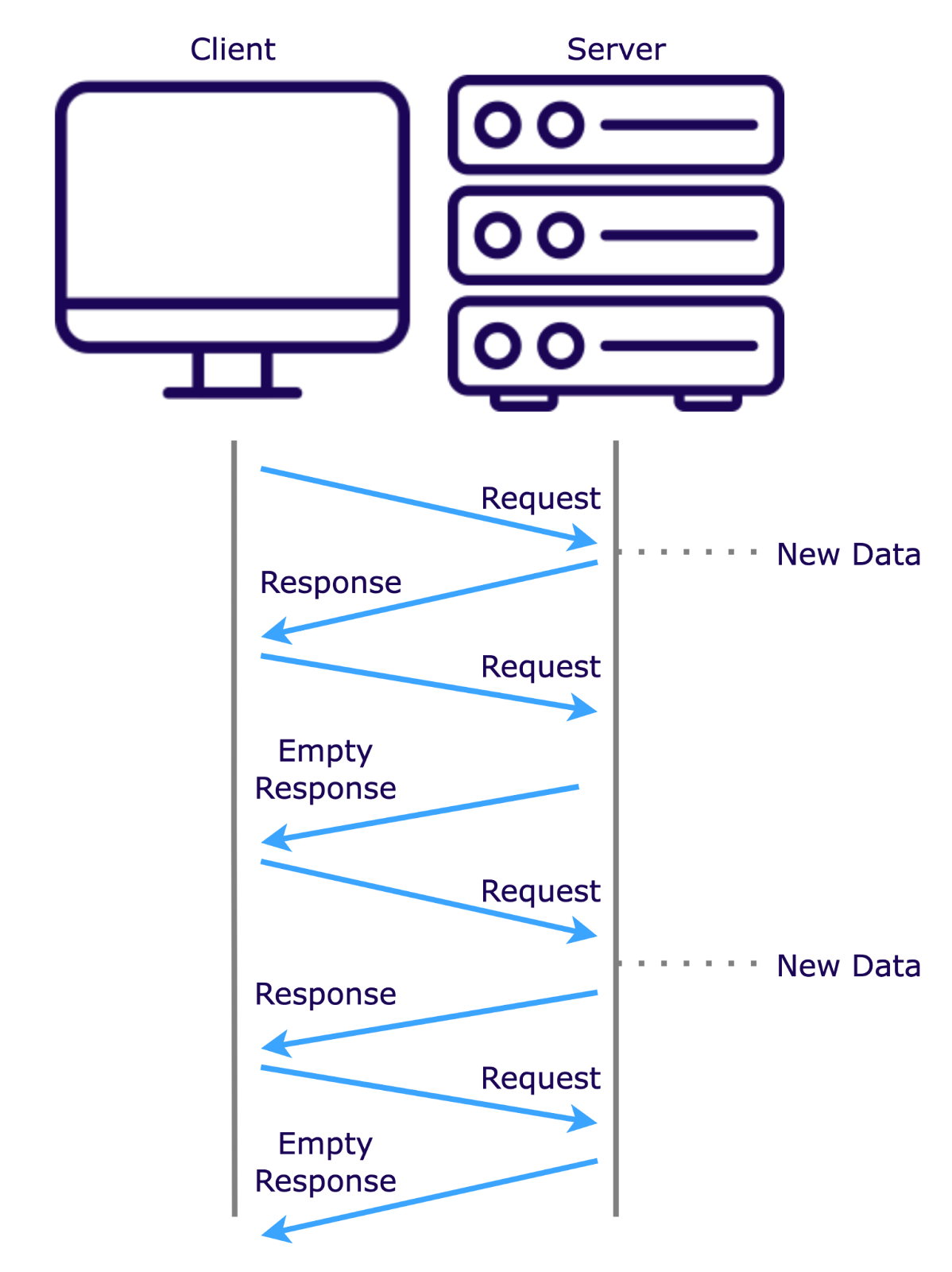
Long polling improves on this by keeping the connection open until new data arrives, reducing redundant requests. However, it still requires the client to initiate each new request, which can lead to occasional synchronization issues.
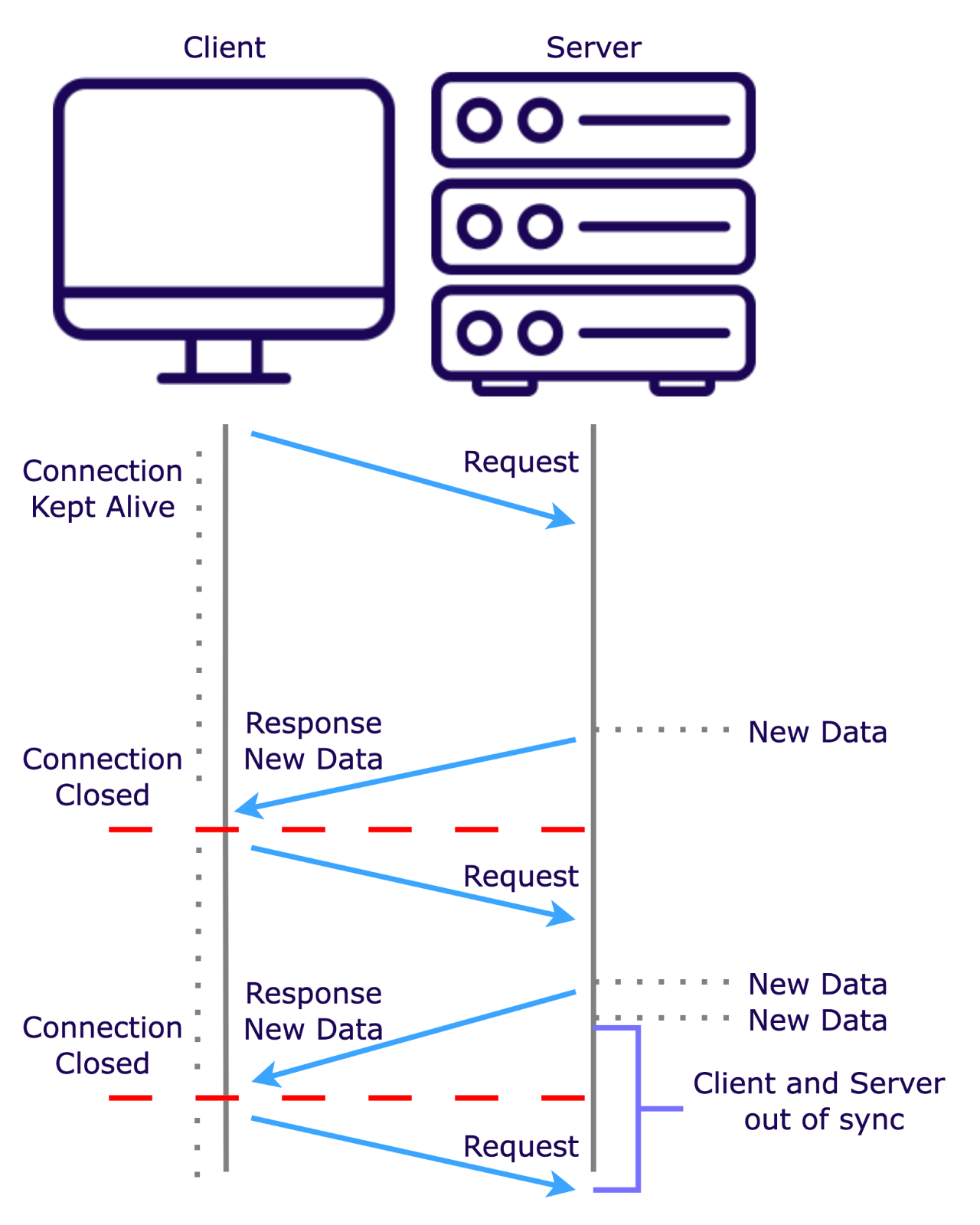
Server-Sent Events (SSEs) further optimize this process by maintaining an open connection where the server continuously pushes updates to the client as they become available, eliminating the need for repeated requests and minimizing latency.
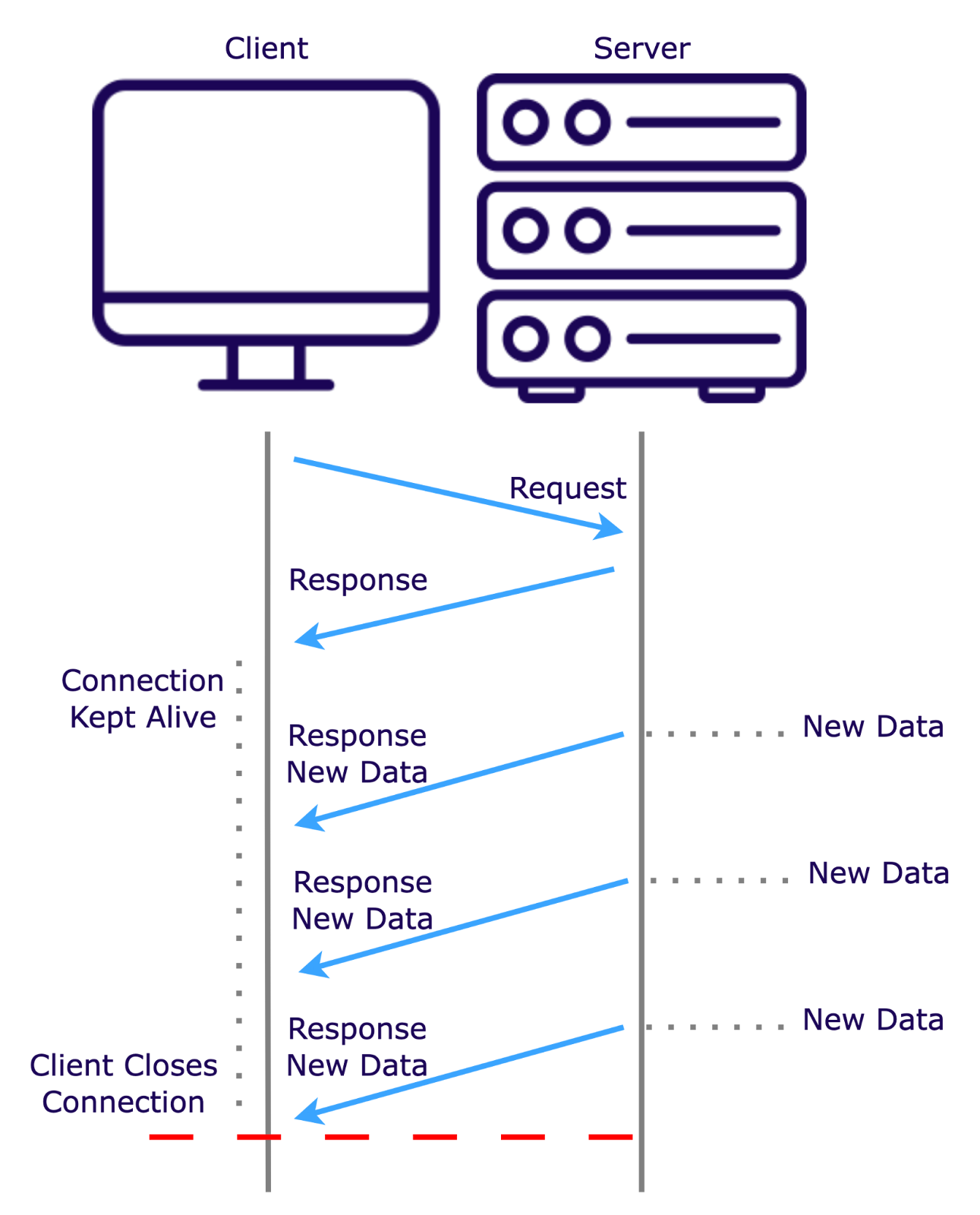
While SSEs are efficient for one-way updates, they do not allow the client to send data back to the server in the same connection. This is where WebSockets excel.
WebSockets
The WebSocket protocol offers full-duplex communication over a single long-lived Transmission Control Protocol (TCP) connection. After an initial “handshake” to establish the connection, a dedicated low-latency channel is created, allowing for instantaneous data exchange in both directions.
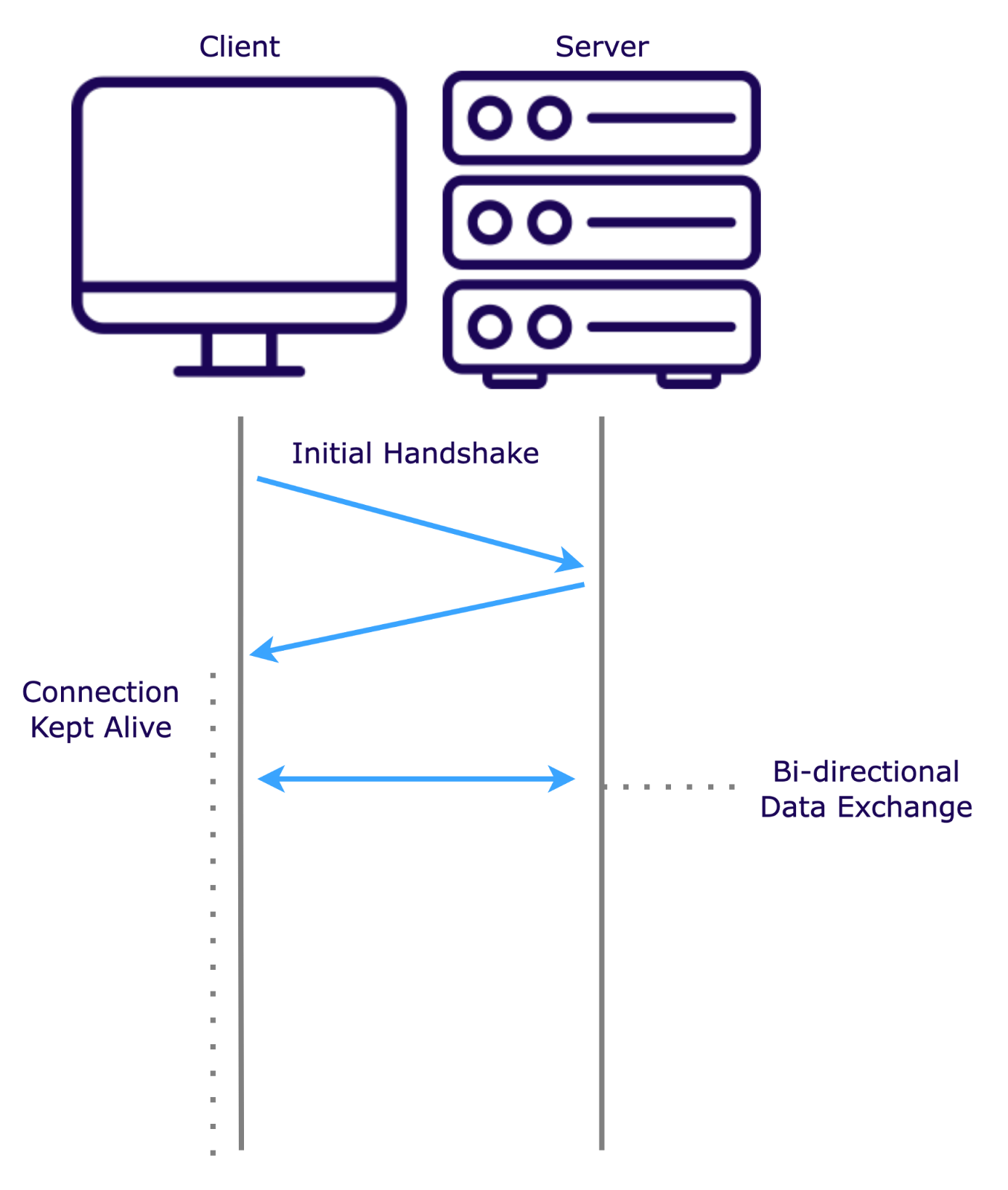
However, WebSockets are complex to set up and manage due to their persistent connection and stateful nature. WebSockets require both browser and server-side support, but their long-standing presence means they are widely compatible across platforms. Additionally, WebSockets suffer from head-of-line blocking, where delays in one message can impact the delivery of subsequent messages.
WebTransport
The WebTransport API is an emerging technology that offers a promising alternative to WebSockets. WebTransport utilizes multiplexed streams and datagrams over HTTP/3 and the QUIC protocol. This setup allows multiple data streams to function independently within the same connection, reducing latency and avoiding head-of-line blocking—a problem in single-stream systems like WebSockets where delays in one packet can affect all subsequent packets. WebTransport’s capabilities make it particularly effective for handling numerous simultaneous realtime data exchanges, such as video streaming or complex online games.
However, WebTransport is still in development and lacks support across all browsers. It also requires server-side support, which is not yet as widely available as WebSocket support.
We determined that WebSockets are the most suitable for our focus and application. However, WebSockets come with distinct complexities, particularly when it comes to scaling.
Scaling WebSocket Applications is Not Trivial
Scaling web applications typically involves vertical scaling, horizontal scaling, or some combination thereof. Vertical scaling involves adding more power to a single server, while horizontal scaling spreads the load across multiple servers.
Scaling realtime WebSocket applications comes with an additional set of unique challenges. It’s helpful to use HTTP-based applications as a benchmark to understand these challenges.
Challenges with State
One of the main differences between HTTP-based applications and WebSocket applications relates to state. In an HTTP interaction, the client initiates a request to the server, which processes the request and sends back a response, after which the connection is terminated. This type of communication is considered stateless because each request is independent and doesn’t rely on information from previous interactions. Because HTTP-based applications are stateless, any server can handle any request, making horizontal scaling more straightforward.
WebSocket applications differ by maintaining an ongoing connection between the client and server, requiring each server to manage the session state and route messages accordingly. This continuity complicates scaling, as servers need to coordinate which clients are connected to them. Unlike HTTP, WebSockets require more infrastructure to maintain these persistent connections.
Challenges with Performance
Servers managing WebSocket connections face a heavier workload than those handling standard HTTP requests. WebSockets’ ongoing connections increase resource consumption, especially memory and CPU. This can lead to performance issues and a poor user experience if not properly managed.
Some applications add realtime features to existing servers that also handle non-realtime tasks. While simple, this "tightly coupled" approach introduces risks as the app scales:
- Performance Bottlenecks: Shared resources can slow down both realtime and non-realtime tasks.
- Scaling Challenges: Realtime and non-realtime components may need to scale differently, making management harder.
- Single Point of Failure: A failure in the server affects both components, increasing downtime risks.
Decoupling the realtime and non-realtime components allows each to scale independently, improving performance and reliability as the application grows.
Dedicated Realtime Infrastructure
Scaling WebSocket applications effectively requires specialized infrastructure. However, sourcing, configuring, and maintaining such infrastructure can be a significant burden for developers, diverting attention away from core product development. A dedicated infrastructure for realtime communication not only alleviates these challenges but also ensures that both performance and state management are optimized for the unique demands of WebSocket applications.
Cerebellum's Niche
For teams with a core focus on realtime, DIY solutions like Node.js' WebSocket library or Socket.io offer complete control and flexibility over data and infrastructure. However, these solutions require significant effort to set up and maintain.
If realtime isn't your core product, third-party solutions like Ably or PartyKit can simplify integration and reduce setup time. These services handle infrastructure and offer easy-to-use abstractions but provide less control over data and customization.
Cerebellum bridges the gap for teams seeking a balance between low effort, high flexibility, and full control over their data.
To help evaluate solutions, we considered several key attributes:
- Data Persistence: Duration and method of storing messages across sessions.
- User Presence: Capability to track and report user status in real time.
- Open Source: Availability of source code for inspection and modification.
- Data Ownership: Control over the data generated and stored.
- Exactly Once Delivery: Assurance that messages are delivered exactly once.
- Auto Scaling: Ability to automatically adjust resources based on demand.
- Multi-Language Support: Compatibility with different programming languages.
- Cost: Overall expenses related to using and scaling the service.
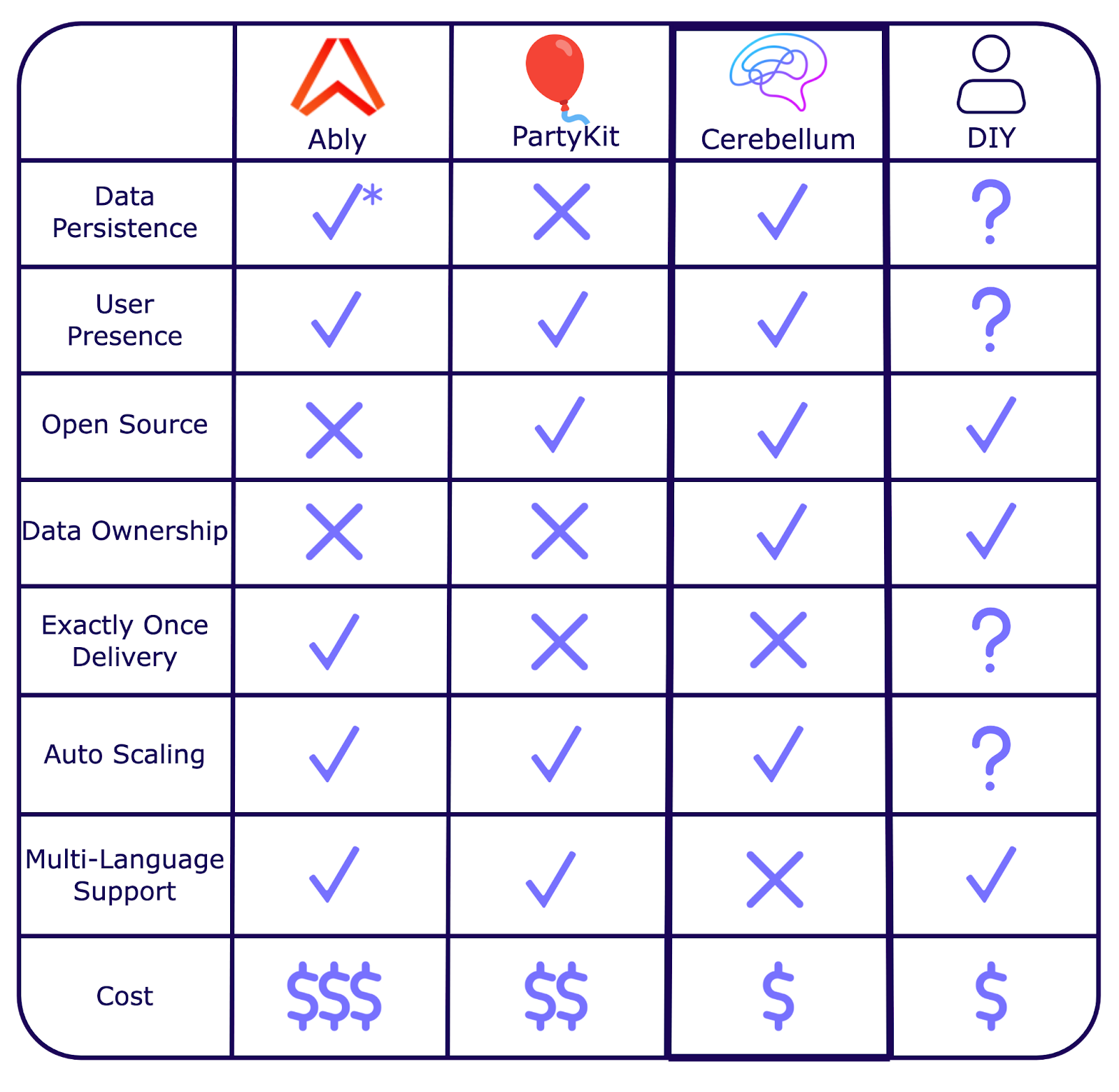
*Ably stores all messages for two minutes by default, with an option to increase to 72 hours in their premium package. Longer data persistence requires a third-party solution.
Cerebellum is built for small to medium-sized development teams who want a realtime solution that handles infrastructure with strong support for data persistence, long-term storage, and an easy-to-use interface.
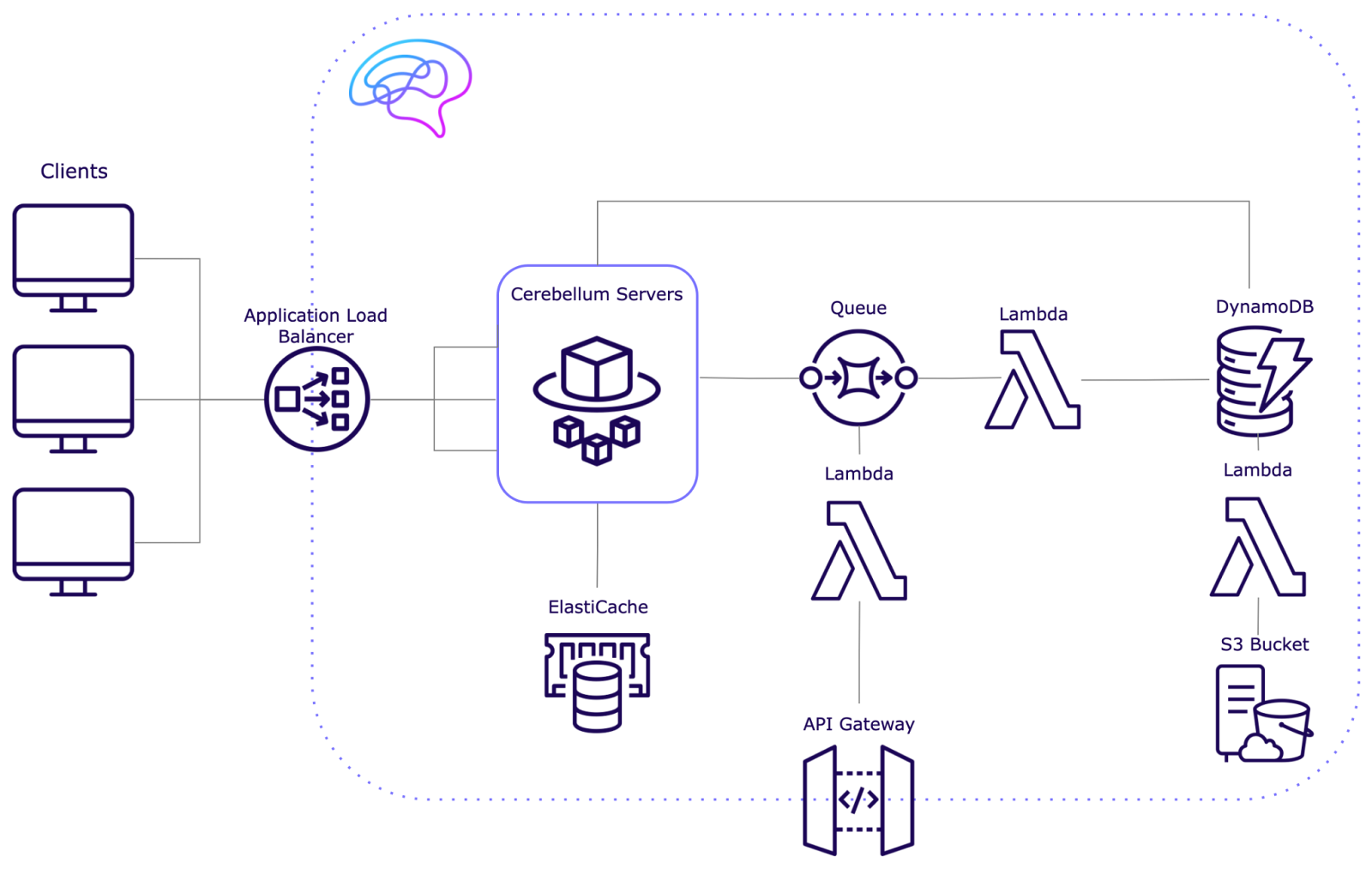
Building Cerebellum’s Infrastructure
Cerebellum was built with scaling in mind. This required provisioning servers for horizontal scaling, ensuring our architecture could maintain performance and reliability as the number of WebSocket connections increased.
The CAP theorem highlights a fundamental trade-off in distributed systems: they can prioritize either availability or consistency, but not both simultaneously. Availability ensures that data requests always receive a response, even if parts of the system fail. Consistency guarantees that all clients see the same data, which can sometimes come at the expense of longer load times.
Since Cerebellum is designed for soft realtime applications, we prioritize availability over consistency.
We chose AWS as our preferred platform to host the infrastructure, due to its extensive service offerings and dominant market share among cloud providers.
Establishing a Connection on a Single Server
We initially built our infrastructure with a single WebSocket server, allowing us to simplify development and focus on creating a stable realtime communication library.
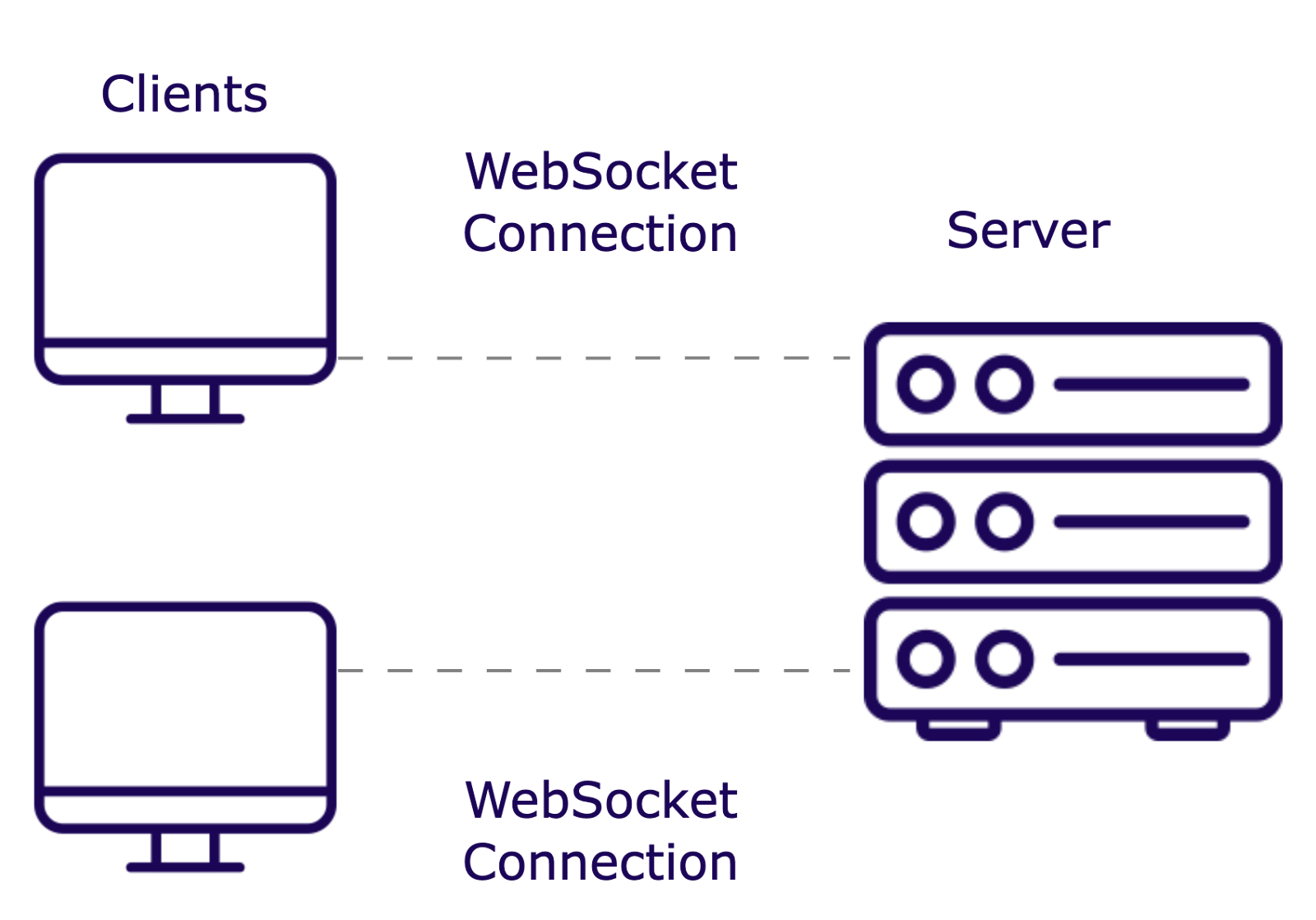
We hosted our WebSocket application on a server with 0.25 vCPU and 0.5 GB of RAM. When we exceeded 4,000 concurrent users, CPU utilization was nearing 70%, which is AWS’s recommended threshold for scaling. Beyond this point, server response times could increase, and the risk of crashes becomes higher without additional resources. Moreover, relying on a single server introduces a single point of failure.
Scaling Complexities with Multiple Servers
Scalable Servers
We used AWS Elastic Container Service (ECS) with AWS Fargate to set up our infrastructure for horizontal scaling. Containers are lightweight, portable units that package an application and its dependencies. These containers are created from images, which are snapshots of the application environment, including the code, libraries, and system settings.
ECS is an orchestrator—it manages the number of containers running at any given time. ECS monitors server load and decides when to scale up or down accordingly. Fargate is a compute engine that eliminates the need to provision and manage servers by creating serverless containers on demand. It allows us to define a Docker or Elastic Container Registry image (our WebSocket server by default) and creates a container with a pre-specified operating system.
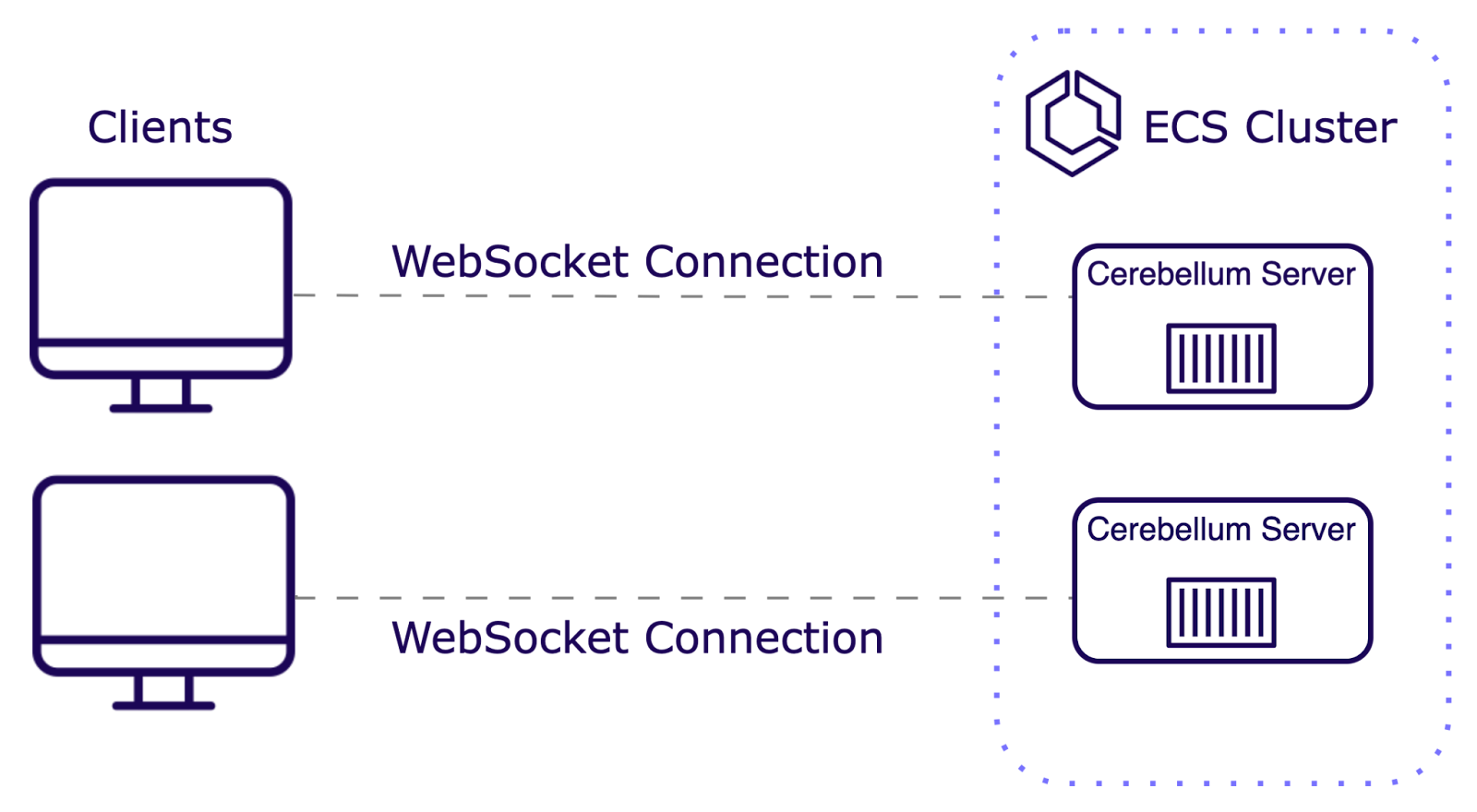
While our infrastructure could now automatically scale based on user load, users connected to different servers couldn't communicate with each other. Each server maintained its own isolated state and connection data. As a result, a user connected to one server wouldn't be able to reach a user connected to a different server.
We needed a way for data to allow data flow and consistency between our servers. We implemented a pub/sub to facilitate this cross-server communication.
Pub/Sub
Publish/Subscribe (Pub/Sub) is a messaging pattern used in distributed systems to facilitate communication between different components. For context around this discussion, we’ll define some key terms related to the pub/sub model:
- Channels (also known as "rooms" or "topics") are communication hubs where messages are exchanged between publishers and subscribers.
- Subscribers are users or systems that receive notifications when a message is sent to a channel they follow.
- Publishers are users or systems that send messages to channels.
In the pub/sub model, publishers and subscribers are decoupled. Publishers can send messages to channels without needing to know who the subscribers are, and subscribers receive messages without knowing who the publishers are.
By implementing a pub/sub system, when a user sends a message to a server, it is received by the pub/sub system and forwarded to all subscribers of that channel, regardless of which server they are connected to. This ensures that all users receive the same information in real time, overcoming the challenges of server isolation and ensuring consistent message delivery across multiple servers.
Redis Streams as Our Pub/Sub System
For our pub/sub system, we used AWS ElastiCache for Redis, specifically utilizing Redis Streams. While Redis is often known for its key/value cache functionality, it also offers powerful features for building robust pub/sub systems.
Redis Streams provides an append-only log data structure that supports more complex pub/sub scenarios. Key advantages include:
- Persistence: Messages in Redis Streams can be persisted, enabling replay and recovery, which is crucial for maintaining the connection state in realtime applications (a key requirement which we will discuss in detail in the Realtime Engineering Challenges section).
- Backpressure Handling: Streams allow servers to regulate the rate of message consumption, preventing overload by controlling the flow of incoming messages.
We selected Redis Streams due to the high availability and low latency provided by AWS ElastiCache.
In our Redis Streams implementation, the message flow differs slightly from traditional pub/sub systems. When a message is published, it is appended to a Redis Stream associated with a specific channel or topic. Each message is stored with a unique ID, ensuring persistence. Servers act as consumers, reading from these streams at their own pace and capacity. After retrieving messages, servers forward them to clients subscribed to the respective channels. This retains the core principles of a traditional pub/sub while also enabling data persistence.
With our Redis Streams-based pub/sub system in place, we had to establish a single, secure public entry point while balancing load across multiple servers.
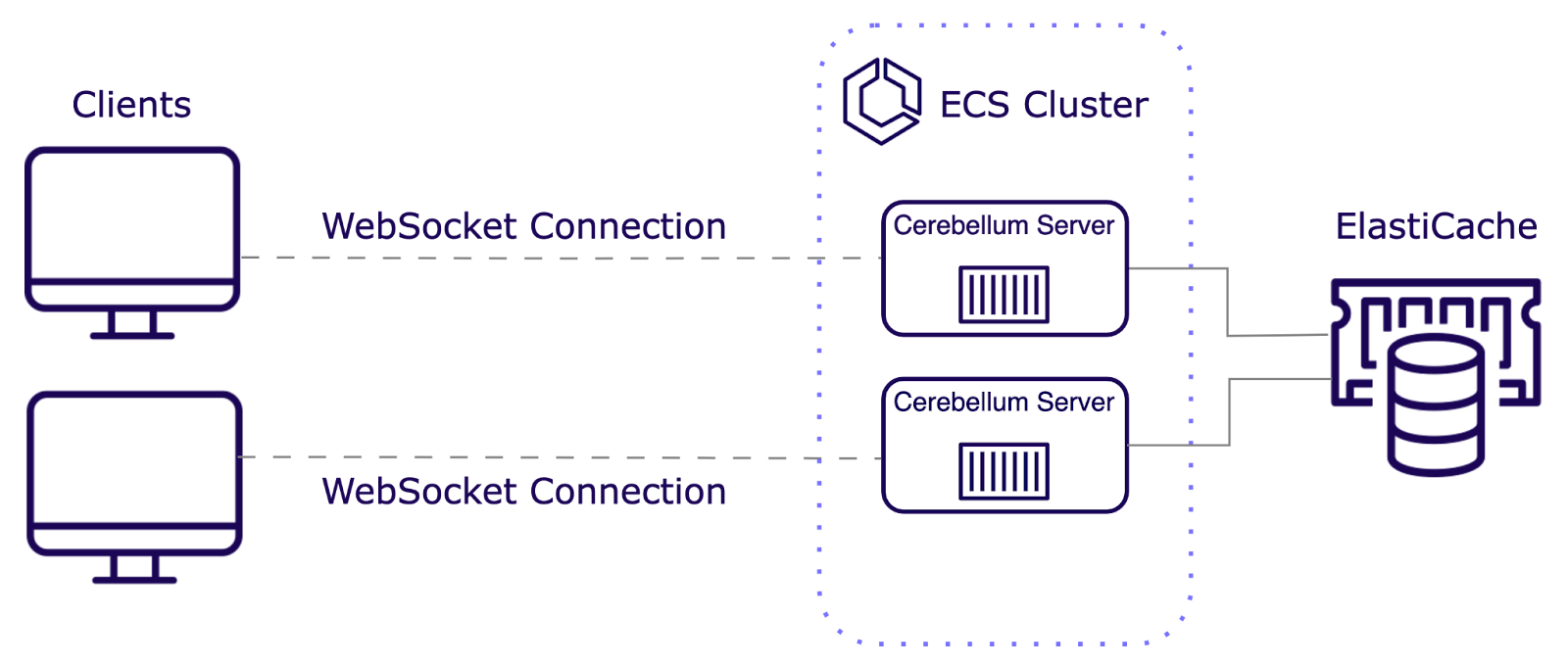
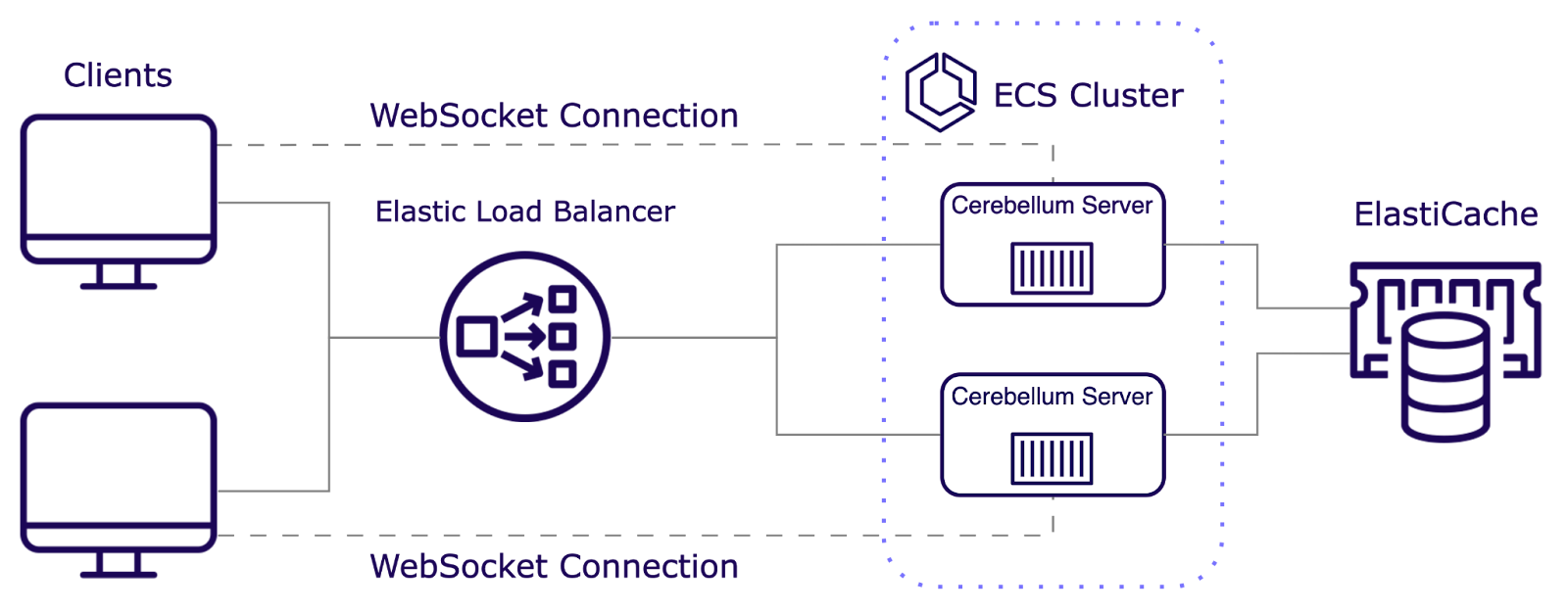
Balancing the Load Distribution
Realtime applications require high availability and fault tolerance to ensure seamless user experiences, even during partial system failures. We use an Application Load Balancer (ALB) to distribute incoming traffic across multiple servers to achieve this. The ALB prevents any server from becoming overwhelmed and enhances overall performance and reliability.
We considered a few options for routing traffic:
- Round Robin: Distributes each request sequentially to the next server. This method works well when traffic is uniform and servers have similar processing power.
- Least Outstanding Requests: Routes traffic to the server with the fewest active connections. This is ideal when request processing times vary and servers have different capabilities.
Since our infrastructure scales by duplicating containers with identical processing power, we initially considered Round Robin. However, we cannot anticipate uniform traffic in the realtime applications. Additionally, when new servers are spun up, we need to route traffic more heavily to them to utilize their increased capacity. Therefore, Least Outstanding Requests was our top choice to ensure a more balanced load across servers.
In addition to balancing load, the ALB provides other key benefits:
- Health Checks: The ALB tracks which servers are healthy/unhealthy and re-routes traffic accordingly.
- SSL/TLS Encryptions: The ALB enforces encryption to protect data between client and server.
By handling these tasks, the ALB solved a crucial part of our infrastructure needs, ensuring the stability and security of our realtime applications while managing server load.
Persisting Data in a Realtime Application
At this stage, our architecture successfully provided realtime scaling and communication, but we recognized a major limitation in the need for historical data access. This is vital for various realtime applications, including:
- Collaborative Editors: Applications like Google Docs need to maintain past revisions.
- Video Conferencing: Services like Zoom provide video recording features.
- Communication Apps: Platforms like Slack require persistent message history.
Choosing the Right Database for Realtime Applications
Considerations when selecting a database for realtime applications were scalability, low latency, high throughput, and flexibility—specifically regarding dynamic data structures. Because these were our major considerations, we ruled out SQL databases, which are more rigid in structure and require complex partitioning when scaling.
With these in mind, we chose AWS DynamoDB. DynamoDB’s ability to distribute data across multiple servers allows for smooth expansion as user bases grow, ensuring that Cerebellum-powered applications remain responsive even under heavy traffic. Its optimized read and write operations are crucial for handling the high throughput required in realtime scenarios. Moreover, DynamoDB’s flexible schema supports the dynamic and evolving data models typical in realtime application development. For these reasons, DynamoDB offers an excellent blend of scalability, performance, and adaptability, making it well-suited to our needs.
Availability vs. Consistency
With our database solution in place, we were faced with balancing availability and consistency in our realtime data interactions. This balance is essential for maintaining the responsiveness expected in realtime applications while ensuring data integrity.
Direct communication between servers and databases in a realtime environment is straightforward and ensures strong consistency, but it also poses several issues:
- Increased Latency: Each database operation requires a round trip between the server and the database, adding delays that can be detrimental in realtime applications where milliseconds matter.
- Connection Overhead: Maintaining numerous open database connections for each user session can strain server and database resources, leading to inefficiencies.
- Database Bottlenecks: High-volume realtime applications can overwhelm databases with rapid read/write requests, potentially causing performance degradation or system failures.
While this method ensures data consistency, the resulting latency and resource strain make it less suited for realtime applications where immediate responsiveness is optimal.
We implemented a queue system between the servers and the database, using AWS Simple Queue Services and AWS Lambda. This approach offers several key benefits:
- Decoupling: The queue buffers operations, letting the realtime server respond to clients without waiting for the database, ensuring quick responses.
- Responsiveness: Servers can process and acknowledge client requests promptly, meeting realtime app expectations.
- Managed Load: The queue controls data flow to the database, preventing performance issues from sudden write bursts.
- Resilience: If the database fails temporarily, the queue holds data until it's ready, minimizing data loss risk.
- Eventual Consistency: While not immediately consistent, the queue ensures all data is eventually processed, preserving integrity.
When a client sends data to Cerebellum servers, the server will immediately timestamp the message and send it to the queue. The server continues to process the request without waiting for a confirmation from the database. When the message reaches the front of the queue, a serverless function will process the message and save it to the database. If the database write fails, the queue can retry the operation or save the data in the dead-letter queue—a special queue where undeliverable or failed messages are sent, allowing developers to analyze and fix issues. This ensures data is not lost.
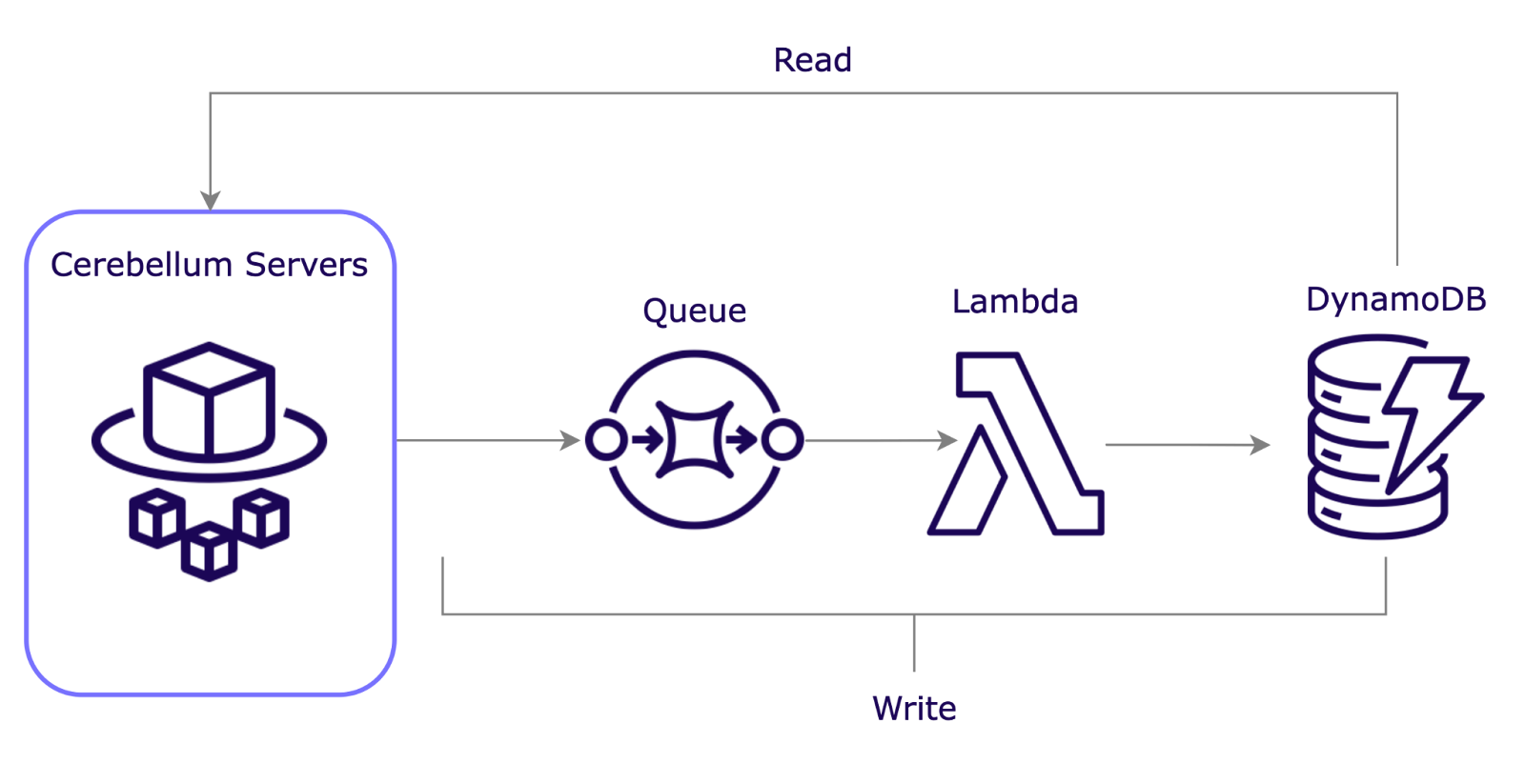
This approach allowed us to prioritize availability while maintaining eventual consistency. Although there is a slight delay in data persistence, this trade-off is minor compared to the performance gains. Overall, DynamoDB’s fast, flexible nature proved to be an excellent choice for handling realtime workloads, even under heavy traffic. However, as data grows over time, the cost of storing vast amounts of information in DynamoDB increases significantly. To address this, we implemented a long-term solution for managing historical data without sacrificing performance or inflating costs.
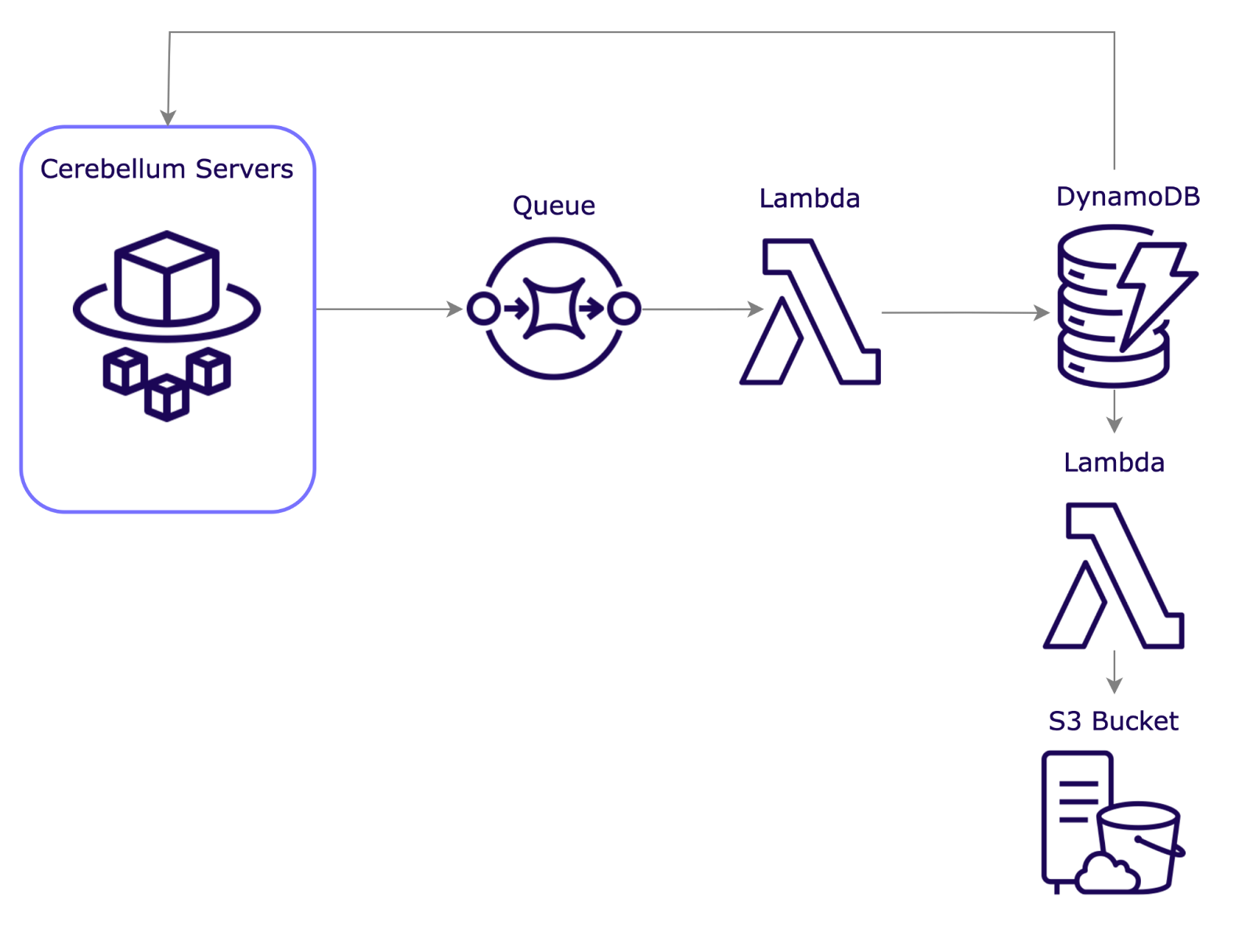
Archiving Data
As DynamoDB tables expand, older data will likely be accessed infrequently or not at all. Leaving this data in DynamoDB can add unnecessary costs to the developer.
Let’s consider a realtime communication platform, similar to Slack. To set up this example, we make the following assumptions:
- 100,000 users per day
- 20 messages per user per day
- 200 bytes per message
- Archive any data older than 1 year
This means that in a 30 day month, we would have:
100,000 users/day * 20 messages * 200 bytes/message * 30 days = 12 GB per month
AWS charges $0.25 per GB per month for DynamoDB. In our example, that would result in:
$0.25 per GB-month * 12 GB = $3 per month
If every message was left in DynamoDB indefinitely, it would result in an additional $3 per month. Over 5 years, the AWS bill for storage alone would roughly cost:
$3 + $6 + $9 + … + $180 = $5,490
If we were to archive all messages older than 1 year, we would get a max storage per year of:
12 GB * 12 months = 144 GB/month
Paying for this across 5 years, the DynamoDB bill would be:
144 GB * 60 months * $0.25 per GB-month = $2,160
If we were archiving every month, this would be ~12GB per month. The cost of storing data in an S3 bucket is $0.023 per GB per month. This means that 1 month of storage in the S3 bucket will cost:
12 GB * $0.023 per GB-month = $0.28
As a result, this storage cost for the S3 bucket over 5 years will be:
$0.28 + $0.56 + $0.84 + … + $16.80 = $512.40
That means the total spent across 5 years would be:
$2,160 + $512.40 = $2,672.40
The cost savings from archiving data would be $2,817.60.
To archive old data, we have automated a cron job that will trigger a Lambda function once per week. This Lambda will retrieve data from DynamoDB, save it as one JSON file to an AWS S3 bucket, and remove it from the DynamoDB table. The developer can define the age that data should be archived within the Lambda function.
HTTP Endpoint
Our servers could now manage both WebSocket connections and HTTP traffic, which includes messages being published from the developer's backend. However, our servers were still tightly coupled.
We implemented a dedicated gateway for HTTP traffic using AWS API Gateway to decouple our servers and preserve performance.
Implementation of API Gateway and AWS Lambda
AWS API Gateway is the entry point for HTTP traffic, efficiently managing API requests and routing them to the appropriate backend services. It automatically scales to handle varying traffic loads, ensuring that HTTP traffic does not interfere with WebSocket connections. Additionally, API Gateway provides built-in features such as throttling and monitoring capabilities to ensure our HTTP endpoints remain performant.
AWS Lambda complements the API Gateway by enabling serverless execution of code in response to HTTP GET and POST requests. This allows us to handle various types of HTTP requests without the need to manage server infrastructure. Lambda's dynamic scalability ensures that our system adapts to changing load conditions while maintaining cost efficiency.
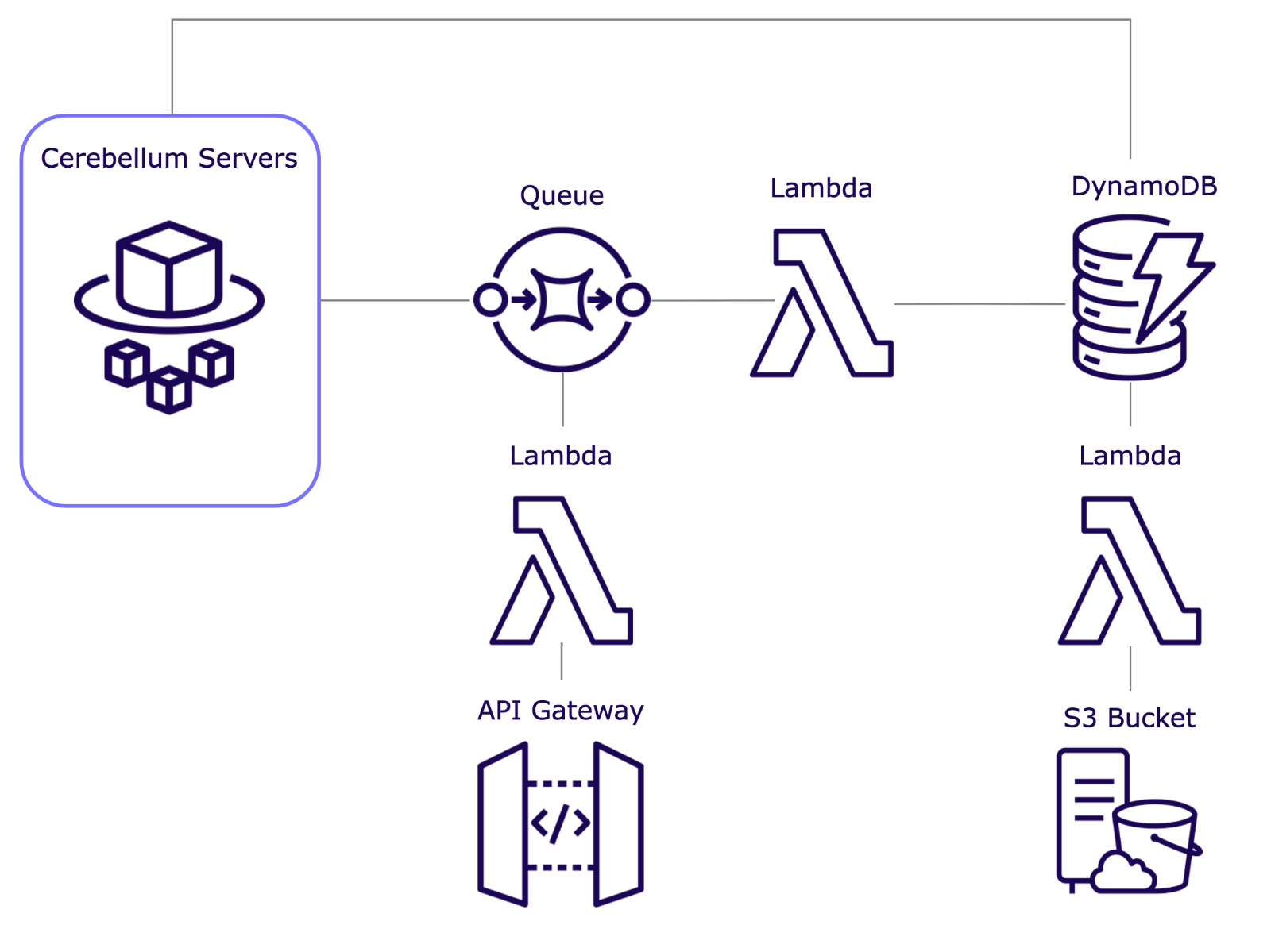
The addition of HTTP endpoints alongside WebSocket connections expands the functionality and flexibility of our system. Key use cases for HTTP endpoints:
- Data Retrieval: Use HTTP GET requests to fetch specific data or initialize application states without needing a persistent WebSocket connection.
- Message Posting: HTTP POST requests allow stateless data submissions like form entries or file uploads when realtime communication isn't needed.
- Integration Opportunities: API Gateway endpoints enable seamless integration with third-party services, allowing external systems to push notifications or updates to our platform.
Integration with DynamoDB and Other Services
Modern applications frequently interact with diverse systems and services, often across various languages and frameworks. REST APIs make this integration straightforward, using standard HTTP methods (GET, POST) and widely supported data formats (JSON). This approach simplifies connecting our DynamoDB database and servers with other services, ensuring smoother and more efficient data interactions.
Final Architecture
This completes the design of our scalable infrastructure. Built to support a wide range of realtime applications, it integrates AWS services to provide reliable, available, and efficient data flow.
Realtime Engineering Challenges
We had a fully formed architecture by this point, but we still needed to handle some of the common realtime application challenges.
Sticky Sessions
Our WebSocket server uses Socket.io to initialize session connections, where a session is defined as a persistent WebSocket connection between the client and the server. The process of initializing a session connection is as follows:
- The client sends an HTTP GET request to the server with `transport=polling` in its query parameters.
- The server responds with a session ID, an array of possible transport upgrades, and other connection-related information.
- The session ID is used by the server to identify the client and manage the connection.
- The list of upgrades typically includes WebSocket as the more efficient and preferred transport method.
- The client will then attempt to set up HTTP long-polling as a default first option.
- The client will then attempt to upgrade the connection to a WebSocket connection by making a GET request with
transport=websocketin the query parameters.
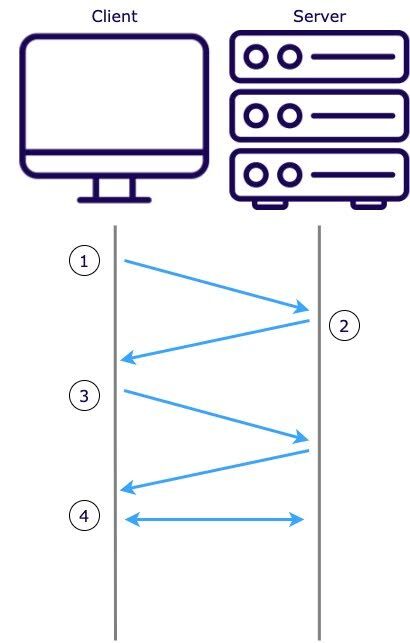
With only one container running, this handshake process can occur without complications. A potential problem arises when we introduce a second container and a load balancer. Due to the multiple round-trip nature of establishing a WebSocket connection, a user may be routed to a container that did not create the ID and thus will not recognize it.
To solve this problem, we implemented “sticky sessions” by generating a cookie with the AWS load balancer and attaching it to each client request. Each subsequent request will receive a cookie in the response and include that cookie value in its request header. The load balancer will forward each request with a recognized cookie to the same server that initially handled it, bypassing the default algorithm. This ensures that the WebSocket connection is created between the associated server and the client.
Connection State Recovery
Users can momentarily disconnect from a server for several reasons—some common occurrences are temporary network outages or transferring from WiFi to cellular data. During this disconnection period, the user is not able to send, receive, or display the current state.
Leveraging our Redis ElastiCache, we provide connection state recovery. This enables users who unexpectedly disconnect to automatically return to the same WebSocket connection, restoring their session state and avoiding re-authentication (outlined in the next section).
In practice, when the client detects a lost connection with the server, it will try to store the last received message ID. No new data can be received during the disconnection period. Upon reconnection, the ALB will redirect the client to the same server via sticky sessions. The server will recognize the WebSocket session ID and attempt to restore the state by retrieving all missed messages from the Redis ElastiCache using Redis Streams. The messages missed between the last acknowledged message ID and the current one are fetched and delivered to the client, ensuring the state is restored.
An added benefit of this process is that upon disconnection, the client will also store any messages that have failed to send. Upon recovery, it will immediately send all buffered messages to the server.
Authentication
In HTTP, it's easy to handle authentication because you can send credentials like tokens with every request. With WebSockets, once the connection is established during the initial handshake, you can’t modify headers or send additional authentication data. This makes it difficult to manage security throughout the session since there's no built-in way to verify the user after the connection is open. To address this for Cerebellum’s WebSocket servers, we implemented token-based authentication to ensure that connections remain secure and properly authenticated throughout their duration.
Token-Based Authentication
A unique API key is generated with AWS Secrets when the servers are first created using our CLI. This API key is injected into every WebSocket server as an environment variable and safely retrievable in your AWS Secrets page. The API key should then be included as an environment variable on your login server.
We recommend using the Cerebellum SDK to generate a short-lived token using your API key upon user authentication. This process ensures that the API key remains secure on your login servers and is not exposed to clients or external parties.
Cerebellum takes the following steps to secure its servers:
- Token Generation:
After a user logs in, the SDK generates a short-lived token tied to your API key. This token has a set expiration time to minimize misuse. - Client Authentication:
When opening a WebSocket connection, the client includes the token in the first message as a temporary credential for user authentication. - Token Verification:
The WebSocket server verifies the token using the API key stored in an environment variable, without needing to query the main database, boosting performance and scalability. - Handling Authentication Failures:
If the token is missing or invalid, the user is denied the connection, preventing unauthorized access and helping protect against DDoS attacks.
By implementing this token-based authentication solution, the WebSocket servers can manage connections securely and efficiently while maintaining high performance and scalability. This approach protects the integrity of the server and ensures that only authorized users can interact with your applications.
Presence
In collaborative and multiplayer realtime applications, knowing who else is in the same channel or workspace is a key feature. Presence allows users to see who is active, what they’re doing, and where they’re working within the document.
Initially, we implemented presence using a traditional pub/sub paradigm, which allowed users to broadcast their presence to others in the same channel. However, this approach had limitations. New users joining a channel could not see who was already present, leading to a lack of awareness and coordination among users. To overcome this, we needed a solution that could effectively manage and synchronize presence information across all users and servers.
Utilizing ElastiCache for Presence
ElastiCache with Redis OSS is an ideal solution for managing presence information in realtime applications due to its exceptional performance and low latency. Redis OSS provides an in-memory data store that supports ultra-fast data retrieval and updates, which are essential for maintaining realtime presence status. Given that Redis was already integrated into our infrastructure for the pub/sub mechanism, extending its use to handle presence data was a natural choice. Its ability to efficiently manage rapid read/write operations makes it perfect for scenarios where user presence is frequently updated. Redis’ immediate consistency ensures that presence information is always current, allowing users to experience realtime changes without delay.
By leveraging Redis as our single source for presence information, we can synchronize presence data across all servers. When a user joins, leaves, or updates their presence information, the changes are immediately reflected in Redis, which is accessible by all servers in the cluster. This update is then broadcasted via the pub/sub system, notifying all users subscribed to that presence channel, and providing a consistent source of presence information for all servers.
How to Handle Disconnections
A key challenge in building presence functionality is managing user disconnections. When a client disconnects, the server must notify other users in the presence channels, as the client can no longer update its status. This prevents stale data in the Redis cache and ensures presence information stays current.
To address this, we assign a unique ID to each client connected to a server. This ID is stored in Redis along with a list of all that user’s presence channels. When a disconnection event is detected, the server automatically iterates through the list of that user’s presence channels and notifies the corresponding presence channel that the user has left. Lastly, the server removes the user’s presence information from the Redis cache to ensure it always has the most up-to-date information for everyone who joins.
Load Testing
Our primary load-testing strategy was focused on determining how many concurrent users a server could handle. To test this, we spun up one Cerebellum WebSocket server on an AWS Fargate container and ran an Artillery test on our cloud infrastructure.
One approach when auto-scaling in ECS is to scale horizontally when the CPU or memory reaches a certain percentage. AWS recommends scaling out at 40% to optimize for performance, 70% for cost, or 50% for a balanced optimization. Per this recommendation, we chose 50% as the default for high performance and reasonable cost efficiency.
Terminology
- Max: Maximum computing resources allocated.
- Baseline: Percent utilization on the Fargate container immediately before the test.
- Peak: Percent utilization on the Fargate container at peak usage during the test.
- Difference: Difference between baseline and peak.
- Idle user: A user that connects to the server via WebSockets and does nothing
- Active users: A user that connects to the server via WebSockets and posts messages to a channel
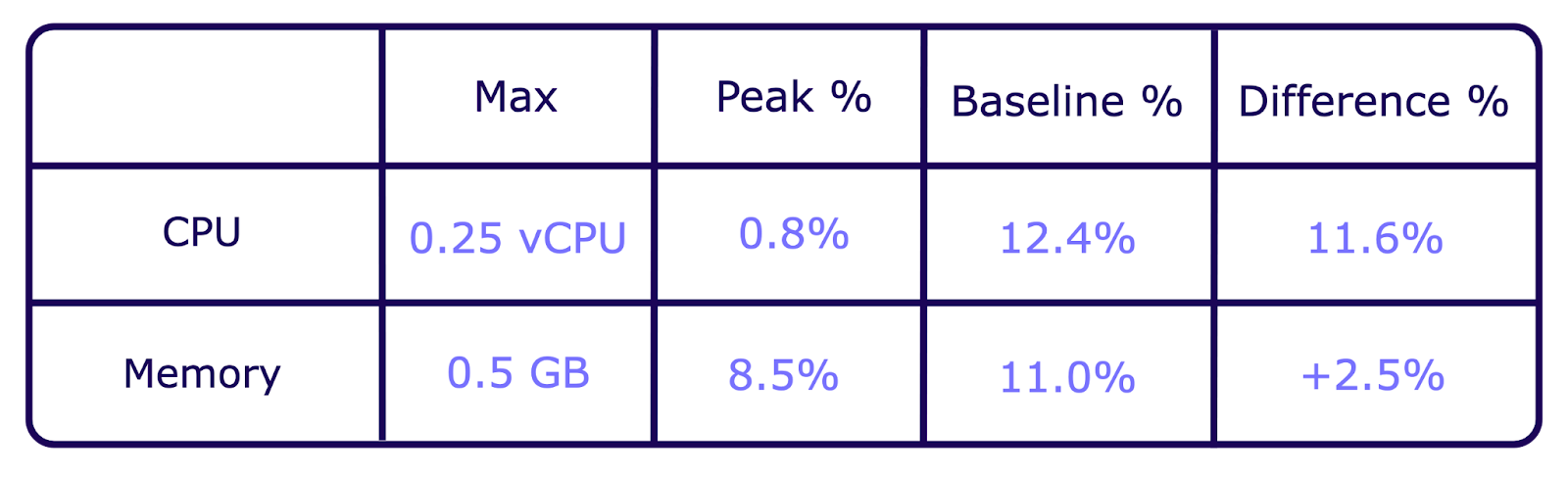
1) Limit of Concurrent Idle Users
- Created 1,000 idle users over 120 seconds
- Recorded Peak CPU and Memory usage
Results:
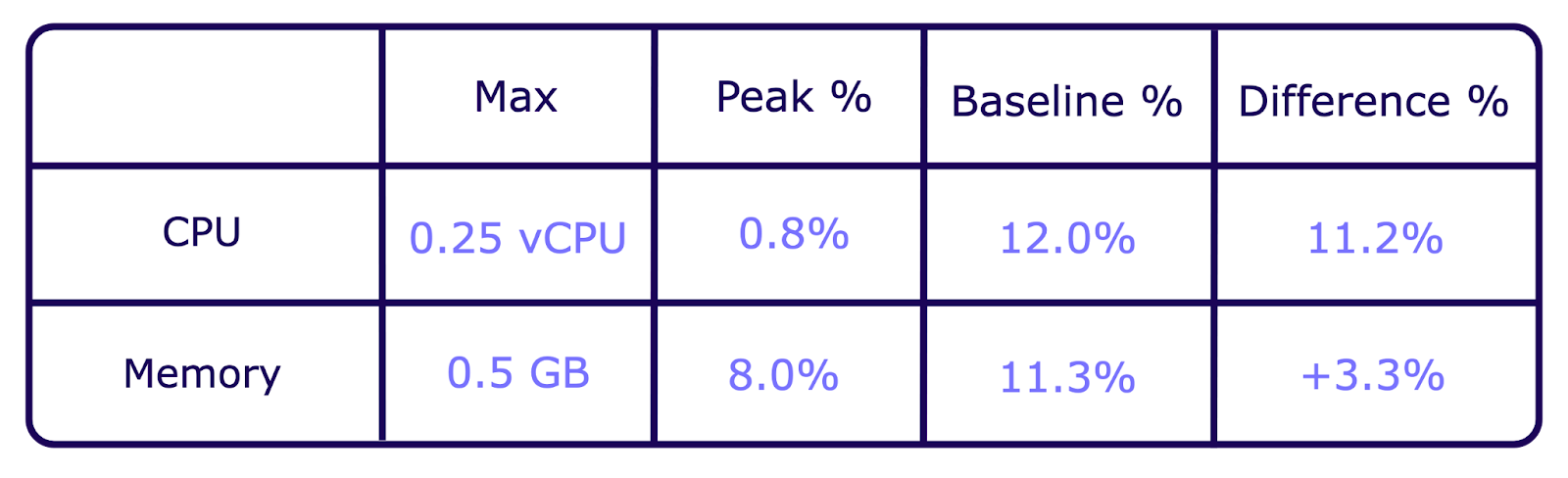
2) Limit of Concurrent Active Users
- Created 1,000 active users over 120 seconds
- Recorded Peak CPU and Memory usage
Results:
Calculations
The limiting factor causing a container to scale is the CPU usage recorded in the idle users test. Assuming a linear relationship, we extrapolated the total number of users that trigger auto-scaling.
Baseline (%) + ( Difference (%) * Scaling Factor ) = Scaling Limit (%)
0.8% + (11.6% * Scaling Factor) = 50% => Scaling Factor ≈ 4.24
Therefore, if we multiply the number of users at peak by the scaling factor, we can estimate how many concurrent users the container can handle before needing to scale.
1,000 * 4.24 = 4,240 users
Conclusion
At 0.25 vCPU and 0.5 GB memory, Cerebellum’s WebSocket servers will comfortably accommodate 4,240 users before auto-scaling.
*These tests are not optimized to test the maximum load that could be placed on our Redis cache. Testing the Redis more extensively would include subscribing and adding presence for multiple users to one channel and testing the strain of the fanning out data and presence across that channel. This is a consideration for future load testing.
In the Pipeline...
Archived Message Retrieval
We’ve implemented automated message archiving to reduce costs by moving older data from DynamoDB to S3. While retrieval is supported, our WebSocket server doesn’t yet automate this. Developers currently handle it manually.
Rate Limiting
In building our WebSocket infrastructure with an Application Load Balancer (ALB), we focused on scalability and ease of integration. The ALB effectively manages WebSocket connections, ensuring high availability and fault tolerance, though it lacks built-in rate-limiting capabilities—an important consideration for protecting servers and ensuring fair usage.
Our current setup doesn’t impose rate limits on incoming WebSocket connections, leaving this aspect to be managed by external solutions or client-side throttling. While API Gateway and AWS WAF offer rate-limiting features, they introduce performance trade-offs and a need for careful cost-benefit analysis due to the complexity of configuring these services for WebSocket workloads.
ElastiCache: Load Testing and Failover
We have not yet tested the physical limit of our ElastiCache. Load testing should be performed by testing channel user limit and presence to determine this limit.
Additionally, this single ElastiCache represents a single point of failure. Our infrastructure would benefit from designating a fallback ElastiCache in case our active ElastiCache crashes.
Cloud-Agnostic Offering
AWS is our preferred cloud provider due to its extensive services and market dominance. However, we understand that other platforms like Azure and Google Cloud also have strong offerings, and some developers may prefer to consolidate resources with a different provider. While our current focus is on AWS, we acknowledge the potential benefits of a cloud-agnostic approach.